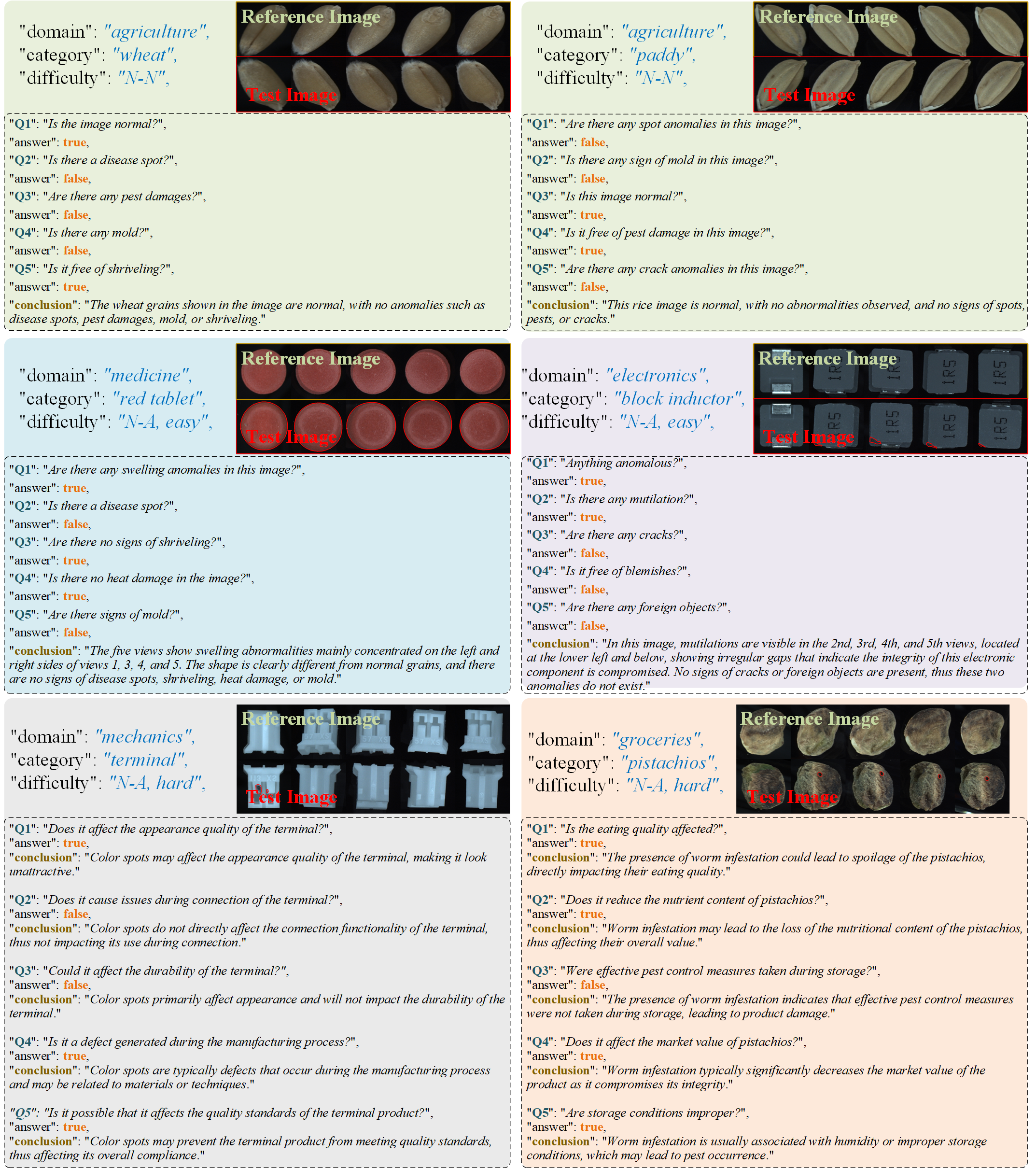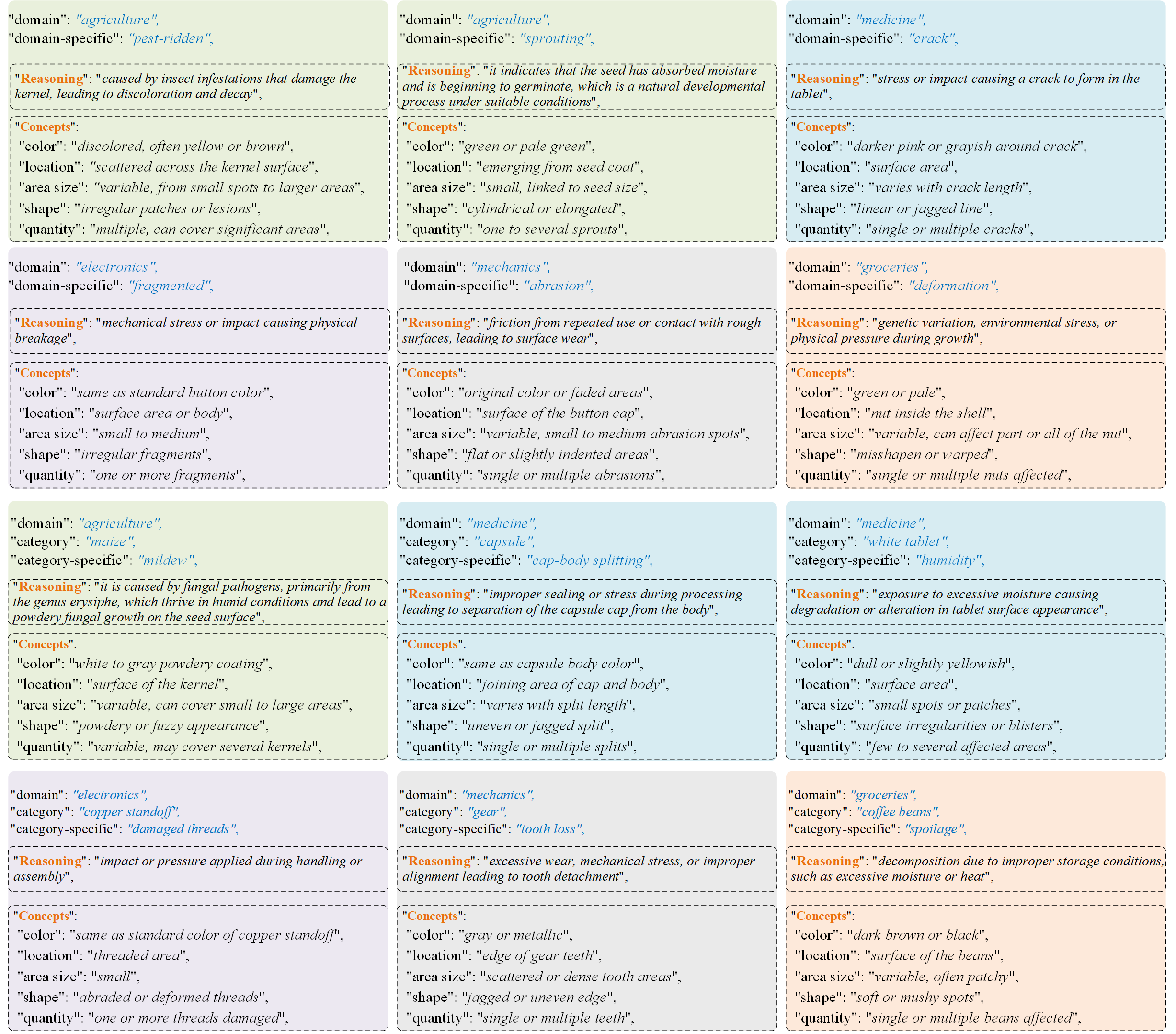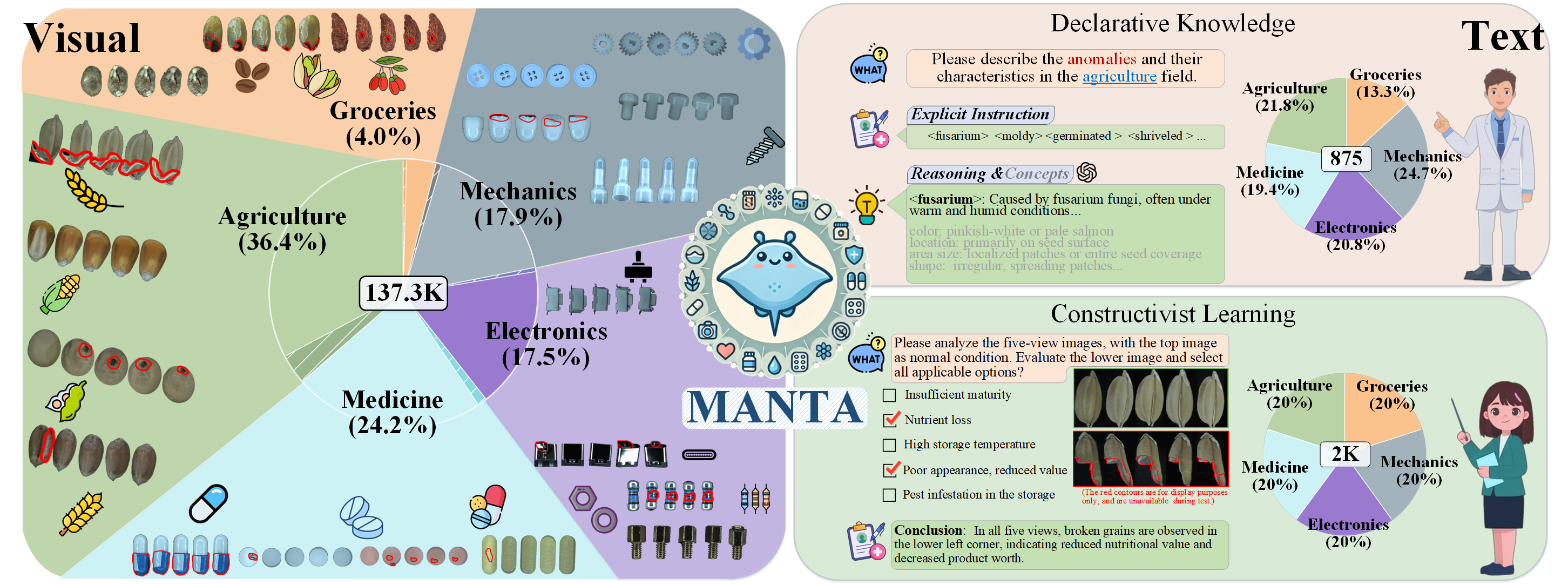
Overview of MANTA. It consists of both visual and text components. The visual part includes over 137K multi-view images spanning five domains. The text part is divided into two subsets: Declarative Knowledge, comprising 875 words describing common anomalies, and Constructivist Learning, which includes 2K Image-text multiple-choice questions.